Data Scuffing Vs Information Crawling What Is The Distinction? Crawling is utilized for information removal from internet search engine and shopping sites, and afterward, you filter out unneeded details and select just the one you require by scratching it. Information crawling, on the various other hand, entails the computerized process of methodically searching the internet or other sources to find and index web content. This procedure is generally executed by software program tools called crawlers or crawlers. Spiders follow web links and go to websites, gathering info concerning the web content, framework, and relationships in between pages. The purpose of creeping is typically to produce an index or directory of data, which can after that be looked or evaluated. Data-driven and, consequently, insight-driven organizations outshine their peers. By tracking customer communication and acquiring a comprehensive understanding of their habits, companies can boost their customer experience. This, likewise, effects lifetime worth and raises brand name loyalty. Information scuffing is just one of one of the most effective means to obtain information from the web, and it does not need the internet to be carried out. Ultimately, different crawl representatives are utilized to crawling different web sites, and therefore you require to guarantee they do not contravene each other at the same time.
Exploring opportunities in the generative AI value chain - McKinsey
Exploring opportunities in the generative AI value chain.
Posted: Wed, 26 https://squareblogs.net/cromliznxk/just-how-to-optimize-e-mail-projects-numerous-alternatives-are-available-to Apr 2023 07:00:00 GMT [source]
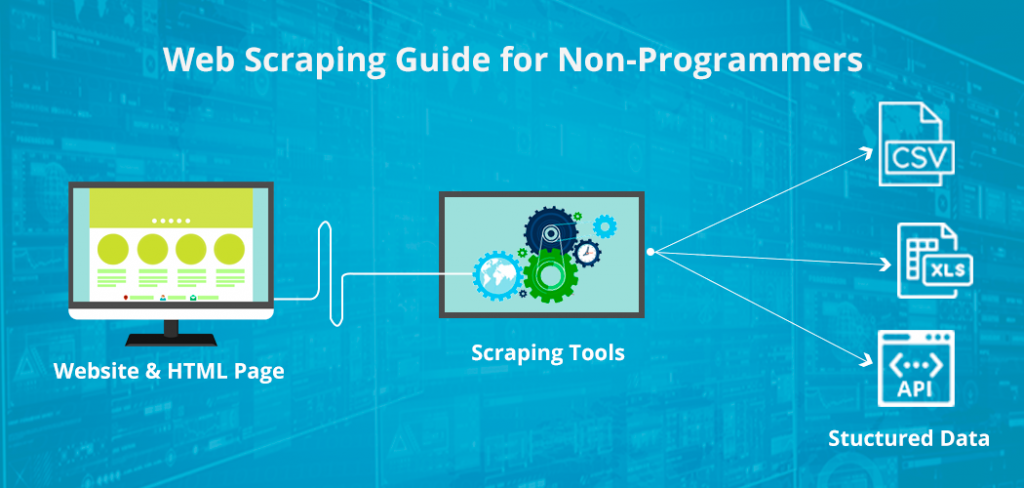

The Devices
This data might likewise include metadata for category functions. Financial services usually use this to collect and examine individual data. Is more usual today than manual "copy/paste." Nonetheless, manually collecting information from website can still benefit smaller sized jobs. Nevertheless, they generally overlap-- so it's simple to interchange these terms. We set up, deploy and keep jobs in our cloud to essence data with best. Requires a room to be saved money on, bringing some costs to the users. If there are JavaScript provided pages, images, or various other formats on the site, it will certainly be much more complex to obtain the data from them. The various other challenge is that web sites are usually upgraded, and your scrape will certainly damage. And it's a big distinction since with scratching you normally know the target websites, you may not understand the details web page Links, yet you understand the domain names a minimum of. If you would like to know more regarding information removal services or are currently thinking about information scratching. And wish to release your data/web scratching project, please get in touch with us today. Do note that information scraping does not simply draw information from the internet; it accumulates it from anywhere the information lives.- Now that we understand both information scraping and creeping ideas, we can move on to the primary differences between both.The internet scrape stores the information in a legible layout for additional evaluation.So with web creeping the result is a lot more simple since it's just a listing of URLs - I mean you can have other fields also yet the major aspects are the Links.And it's a huge distinction since with scraping you usually know the target sites, you might not recognize the specific page Links, but you understand the domain names at the very least.To get a much better understanding of their distinctions, you must grasp what each process indicates and exactly how they work.